Waymo, the self-driving car subsidiary of Alphabet hopes to advance the state of artificial intelligence by providing researchers with new data for their projects.
Today Waymo released a massive repository of sensory information collected during the testing of its autonomous vehicles. The data set includes 1,000 video segments recorded under a variety of road and lighting conditions.
The dataset doesn’t seem huge at first: the 1,000 segments are each 20 seconds long, adding up to around five and a half hours of footage.
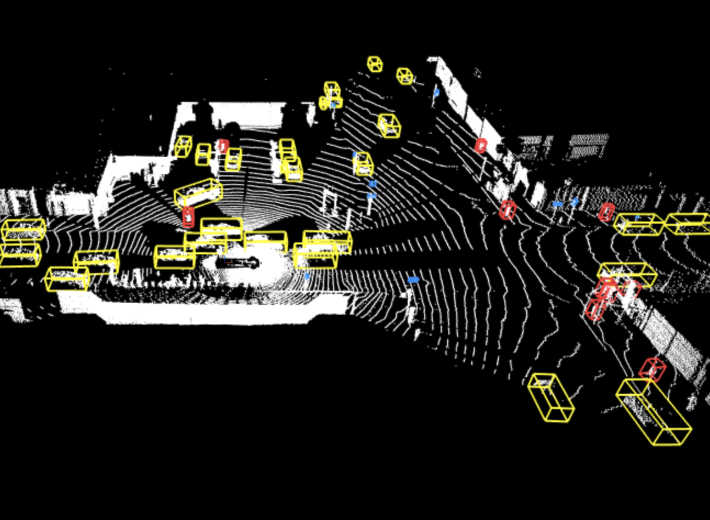
But every segment is 200,000 frames each constituting data points useful for researchers. With individually labelled vehicles, pedestrians, cyclists and signage as they appear in the videos, resulting in at least 13.2 million data tags overlaying these frames.
Another factor making this data uniquely valuable for is the method with which it was assembled. Waymo says the driving segments stitch together footage from five different cameras on the front and sides of its self-driving cars, creating a 360 view. The files also include an added layer of environmental data gathered by the multiple lidar sensors the vehicles.
In a blog post, Waymo principal scientist Drago Angelo wrote:
“We believe it is one of the largest, richest, and most diverse self-driving datasets ever released for research… When it comes to research in machine learning, having access to data can turn an idea into a real innovation,” Angelo wrote. “This data has the potential to help researchers make advances in 2D and 3D perception, and progress on areas such as domain adaptation, scene understanding and behavior prediction.”
While the licensing terms restrict use to non-commercial projects. Waymo’s dataset can potentially lend itself to applications beyond self-driving cars. Like developing computer vision algorithms for robots, or video analysis software.
Header Image: Waymo
I go by Bill Wishbone, not the cool one who played for the 49ers. In the interest of full disclosure, I write under a nom de plume. With that said, this my ethics statement. I will not cover any company I have been employed by within the last two years.
As this news site grows, monetization may well include, sponsored posts or affiliate links, these will always be disclosed within the individual post.
An open challenge to cowardly fraudster Elon Musk to do the same!
The first frame, the demo default, is someone being pulled over by the police…?
https://twitter.com/jonathanfly/status/1166851663275032576